









代理IP的使用

http://httpbin.org/get
-
用浏览器先访问测试网址下看看
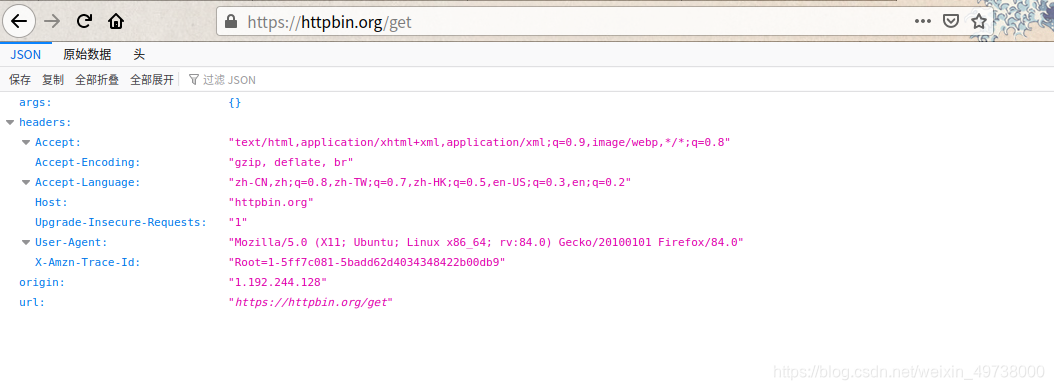
-
再用我们写的代码简单请求一下网页看看
import requests
url='http://httpbin.org/get'
html=requests.get(url=url).text
print(html)
"""
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.23.0",
"X-Amzn-Trace-Id": "Root=1-5ff704d4-3841771516040beb29f6066f"
},
"origin": "1.192.244.128",
"url": "http://httpbin.org/get"
}
"""
疑惑???
“User-Agent”: “python-requests/2.23.0”
网站如何来判定是人类正常访问还是爬虫程序访问? —> 检查请求头!!!
我们是不是需要发送请求时重构一下User-Agent???
添加 headers参数!!!
那就使用fake_useragent 模块
让它伪造一个出来再试试
import requests
from fake_useragent import UserAgent
url='http://httpbin.org/get'
headers={'User-Agent':UserAgent().random}
html=requests.get(url=url,headers=headers).text
print(html)
"""
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6",
"X-Amzn-Trace-Id": "Root=1-5ff7a4de-05f8d7bf49dfe85e3be31d79"
},
"origin": "1.192.244.128",
"url": "http://httpbin.org/get"
}
"""
“User-Agent”: “Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6”
添加好headers的参数就可以了吗?
这还不行吗!!!

一些网站不但检测 请求头
一个IP 异常请求频繁(访问频率过多) 封禁?
“origin”: “1.192.244.128”
这是一项就是博主的IP, 我怎么确定这就是我的IP呢?
查询一下:果真如此
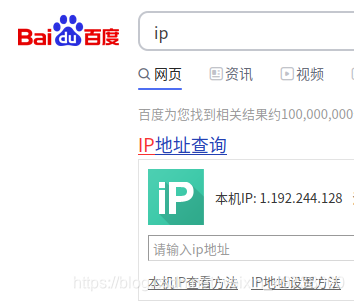
找个免费的代理IP来包装下
- 定义
代替你原来的IP地址去对接网络的IP地址 - 作用
隐藏自身真实IP, 避免被封 - 获取代理
IP网站
快代理、全网代理、代理精灵、… …
这次加上代理IP再去请求下
import requests
from fake_useragent import UserAgent
url='http://httpbin.org/get'
headers={'User-Agent':UserAgent().random}
# 参数类型
# proxies
# proxies = {'协议': '协议://IP:端口号'}
proxies = {
'http': 'http://{}'.format('8.129.28.247:8888'),
'https': 'https://{}'.format('8.129.28.247:8888'),
}
html=requests.get(url=url,headers=headers,proxies=proxies).text
print(html)
"""
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5ff7a71d-10b181340f8dc04f7514dfba"
},
"origin": "8.129.28.247",
"url": "http://httpbin.org/get"
}
"""
“origin”: “8.129.28.247”
这次和我们加入的IP一样, 而不是我们自己的IP直接去请求了
但这一个够用吗?

别着急往下看啦~~~
建立代理IP池
构建一个IP池
每次让它随机提供一个来请求不就解决一个IP请求频繁而导致封掉了
这样就达到我们想要的结果了
- 定义一个测试函数
import requests
from fake_useragent import UserAgent
test_url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().random}
# 参数 IP 地址
def test_proxy(proxy):
'''测试代理IP是否可用'''
proxies = {
'http': 'http://{}'.format(proxy),
'https': 'https://{}'.format(proxy),
}
# 参数类型
# proxies
# proxies = {'协议': '协议://IP:端口号'}
# timeout 超时设置 网页响应时间3秒 超过时间会抛出异常
try:
resp = requests.get(url=test_url, proxies=proxies, headers=headers, timeout=3)
# 查看状态码
if resp.status_code == 200:
print(proxy, '\033[31m可用\033[0m')
else:
print(proxy, '不可用')
except Exception as e:
print(proxy, '不可用')
get一下HTTP状态码
完整代码
# 建立属于自己的开放代理IP池
import requests
import random
import time
from lxml import etree
from fake_useragent import UserAgent
class IpPool:
def __init__(self):
# 测试ip是否可用url
self.test_url = 'http://httpbin.org/get'
# 获取IP的 目标url
self.url = 'https://www.89ip.cn/index_{}.html'
self.headers = {'User-Agent': UserAgent().random}
# 存储可用ip
self.file = open('ip_pool.txt', 'wb')
def get_html(self, url):
'''获取页面'''
html = requests.get(url=url, headers=self.headers).text
return html
def get_proxy(self, url):
'''数据处理 获取ip 和端口'''
html = self.get_html(url=url)
# print(html)
elemt = etree.HTML(html)
ips_list = elemt.xpath('//table/tbody/tr/td[1]/text()')
ports_list = elemt.xpath('//table/tbody/tr/td[2]/text()')
for ip, port in zip(ips_list, ports_list):
# 拼接ip与port
proxy = ip.strip() + ":" + port.strip()
# print(proxy)
# 175.44.109.195:9999
self.test_proxy(proxy)
def test_proxy(self, proxy):
'''测试代理IP是否可用'''
proxies = {
'http': 'http://{}'.format(proxy),
'https': 'https://{}'.format(proxy),
}
# 参数类型
# proxies
# proxies = {'协议': '协议://IP:端口号'}
# timeout 超时设置 网页响应时间3秒 超过时间会抛出异常
try:
resp = requests.get(url=self.test_url, proxies=proxies, headers=self.headers, timeout=3)
# 获取 状态码为200
if resp.status_code == 200:
print(proxy, '\033[31m可用\033[0m')
# 可以的IP 写入文本以便后续使用
self.file.write(proxy)
else:
print(proxy, '不可用')
except Exception as e:
print(proxy, '不可用')
def crawl(self):
'''执行函数'''
# 快代理每页url 的区别
# https://www.kuaidaili.com/free/inha/1/
# https://www.kuaidaili.com/free/inha/2/
# .......
# 提供的免费ip太多
# 这里只获取前100页提供的免费代理IP测试
for i in range(1, 101):
# 拼接完整的url
page_url = self.url.format(i)
# 注意抓取控制频率
time.sleep(random.randint(1, 4))
self.get_proxy(url=page_url)
# 执行完毕关闭文本
self.file.close()
if __name__ == '__main__':
ip = IpPool()
ip.crawl()
测试完这里博主的脸可能比较黑吧, 竟没几个可以用的!!!
由于提供的免费IP可用的机率很小
想构建自己的IP池的小伙伴, 可以去获取其它代理, 提供的免费代理IP.
这里给大家提供几个博主当时测试时可以使用的IP

159.203.44.177:3128
203.202.245.62:80
8.210.88.234:3128
89.187.177.106:80
89.187.177.106:80
96.113.165.182:3128
IP的响应速度根据你机器所在的地理位置不同而有差异
作者:淮南子.
来源:CSDN
版权声明:本文为博主原创文章,原创不易,请尊重原创转载请附上博文链接!















 1466
1466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









